
Can you tell us about your background, Erik?
I finished university in the mid-90s where I studied information management with topics like information theory, data modelling, knowledge theory and AI. I spent the first ten years of my career working on digital transformation in the financial services. Amongst others working on projects to help banks move to the internet and supporting them with their digital architecture.
Then around 17 years ago, I switched to the healthcare sector and started by putting in ERP software for back offices at academic medical centres, redesigning their processes and implementing new systems. By then, the first hospitals in the Netherlands were moving away from their scattered landscapes of point solutions and paper-based systems and starting to put integrated EMR suites in place. I helped in the implementation of EMRs at different hospitals, including quality assurance and providing advice on health terminology.
As a program director I led the largest EMR rollout in the Netherlands at Erasmus MC in Rotterdam and supported them with putting in place the digital backbone for their new hospital build. It’s a smart hospital with many innovative features such as medication robots, self service check-in and apps for nurses and clinicians. We also started with initiatives to share data with other providers in the region using the EMR of the same vendor.
When did you first discover openEHR?
Well, things changed a couple of years ago. As the demand for sharing data outside the hospital continues to grow rapidly, it is crucial to ensure fluent data flow not only within the hospital but also beyond its boundaries.The current situation in healthcare highlights the need for better integration of health and social data across organisations. However, the existing systems are unable to effectively connect and combine the large volume and diverse nature of data being generated. This poses a significant challenge for integrated care as data linkages are incomplete and not optimised for maximum benefit. As a result, the potential for seamless and comprehensive care is hindered. The single vendor strategy as seen with some large health management organisations in the US is expensive and unsustainable. Acquiring a new hospital group with a different solution requires a costly re-implementation and this single vendor strategy gives excessive power to the vendor. And even with a single vendor, fluent data flow is not guaranteed.
The existing data models in these solutions were not designed for sharing data, as they were created with a focus on administrative processes and digitalising existing – mostly paper based – processes in mind, rather than with data in mind. They lack common semantics and are based on the vendor’s proprietary understanding of data models.
To tackle this challenge, we focused our efforts on finding best practices around data sharing around the globe. We conducted a lot of research and engaged in international studies on interoperability. Also in the Netherlands where I’m based, we found that while most countries were spending a lot of money, they were not very successful in achieving their interoperability goals. Yes, there was more sharing – or piling up of documents – but the clinicians were not happy with the progress.
Although it was already on the radar, we started to have a much closer look at openEHR, which was gaining traction in Europe. We found that a group of German Academic Medical Centers organised around HiGHmed had selected openEHR as their standard. I thought ‘why would these hospitals choose openEHR when there’s HL7 FHIR?’ We realised it was key to manage health data in a vendor neutral and open data layer where applications and new ecosystems could be built on top. And openEHR seemed a perfect match for this. But before actually recommending this we wanted to get our hands dirty and figure out how it would work in the cloud in a federative setup so providers could choose and manage their own open data nodes. We wanted the data layer to be vendor-neutral and sustainable, so we selected two different makes of clinical data repositories, dropped them on Microsoft Azure, and created a federated data layer out of that. We branded this design ‘Connected Health Cloud’.
Can you tell us more about the Connected Health Clouds? How do they work?
Primarily it’s a design, it’s an understanding of how you put open standards to work. It’s really the design to create a vendor neutral, semantic rich data layer with open APIs.
The goal was to create an open data layer that is vendor neutral, meaning that organisations, countries, and regions can choose their preferred vendor. We have designed a solution to show clients the art of the possible. The design is fully based on open standards and can run in the cloud, with data nodes that are hooked into federations, allowing a single node to become a certified member of multiple federations. The data nodes can both run in the cloud or on premise when preferred. Important is that providers entrusted with health data of their patients have full control over these data nodes.
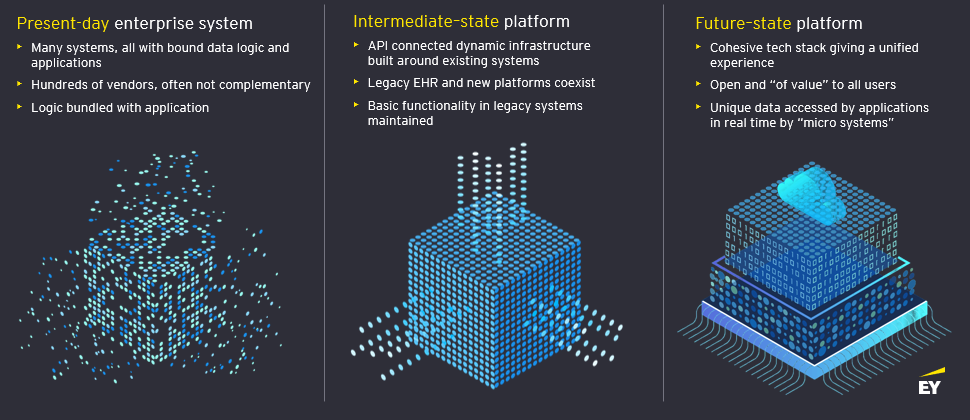
The solution also proves that repositories from different vendors can be federated, enabling end-users and app developers to query data from multiple sources with a single query. Data governance is crucial, and the smoother the mechanism for managing it, the easier it is to create agility. To this end, EY tested a core feature of openEHR – the template – that can be pushed to the entire federation with a single action. All the data nodes immediately, with zero coding, understand the data models provided in these templates.
So the effort is not the technology. The effort is on creating consensus around the data models for a specific use case whilst leveraging the standard well curated international data models openEHR provides.
Is this product available now?
It’s not a cloud product you can buy as a software as a service; health systems will need to create their own setup integrated with for instance country specific services. But they can of course leverage the design and we’re happy to work with health systems to do so. We believe it’s key that health systems know that, if they want to work on a future proof infostructure, that it actually can exist. And the repositories for the data nodes of course are available today and are extensively proven to work.
The focus is on creating a common agreement on the data elements that will be used in practice, rather than just discussing theoretical concepts. The question is whether this approach is actually being implemented by different health systems, and whether they are using cloud technology.
It is important for the data to be vendor-neutral on a cross-organisational level, as being dependent on a specific vendor goes against the principles of openEHR. Therefore, it is necessary to have the flexibility to choose a vendor based on price and capabilities.
How is openEHR being used in the Netherlands?
There are already vendors in the Netherlands who support openEHR, such as Code24 and Nedap. They are mainly active in elderly and mental care. On a national level, there is still work to be done in terms of creating a semantic vendor-neutral data layer, and the country is just starting to explore the possibilities for use in integrated care settings. It is becoming increasingly clear that a standard like openEHR is necessary, and more and more people are beginning to understand this.
Vendors are also starting to build open repositories as part of their solution, like Nedap decided to do several years ago, indicating that it is a common sense choice for engineers. While the Netherlands may be ahead in some areas, they are lacking in others, and Catalonia is a good example of a region that is ahead in terms of data sharing infrastructure. They already have a working infrastructure in place, and are now replacing it with an openEHR one to take things to the next level.
For The Netherlands we’ve already localised the Connected Health Cloud design together with Microsoft, Better, and Open Line, a local managed services company. We have also incorporated XDS and FHIR in this design. In a market sounding for a regional implementation, this design resulted in a high score of 9.2 out of 10.
How does EY bridge the gap between FHIR and openEHR, and what challenges do you foresee in this effort?
Although it may be difficult for some people to digest, this is the point being made in papers, speeches and blogs. For laymen, understanding the difference between FHIR and openEHR, and bridging the gap between them can be challenging. HL7 FHIR is a modern standard designed to facilitate the transfer of data from point A to B. However, it is not specifically designed for creating a comprehensive data layer, and there is a lack of standardisation regarding semantics within HL7 FHIR.
Take, for instance, clinical observations. FHIR has a data object (a ‘resource’) named Observation for sharing information about clinical observations between systems. Observations play a crucial role in the medical field, and there are numerous types of observations. However, even simple observations like body weight or body height lack standardisation within HL7 FHIR. Although profiles can be created for them, these profiles are not governed. Consequently, in real-life scenarios, different data models are used to share the same information. To bridge the gap between FHIR and openEHR, it is essential to address these semantic challenges. The advantage of combining FHIR with openEHR is that the semantic richness and the storage and querying capabilities of openEHR contribute to the development of a truly vendor-neutral open data layer.
With AI going from strength to strength, could a tool like ChatGPT signal the end of unstructured data?
I believe that may not necessarily be the case. Generative AI has the potential to assist with coding tasks, provided it is trained on reliable and structured datasets. For example, generative AI could enable hands-free recording of structured data. However, to achieve this, a semantic-rich data structure and algorithms trained on a well-structured medical corpus are essential. Structured data plays a critical role in conducting reliable research and enabling accurate filtering and sorting for interpretation by medical professionals. Algorithms learn from these datasets, and any inaccuracies in the source data can lead to dangerous mistakes. Promising developments, such as large language models, have already been tested to support radiologists in structured reporting. Nevertheless it will remain important to ensure proper supervision and feeding from reliable data sources to maintain its reliability and effectiveness over time.
Leave a Reply